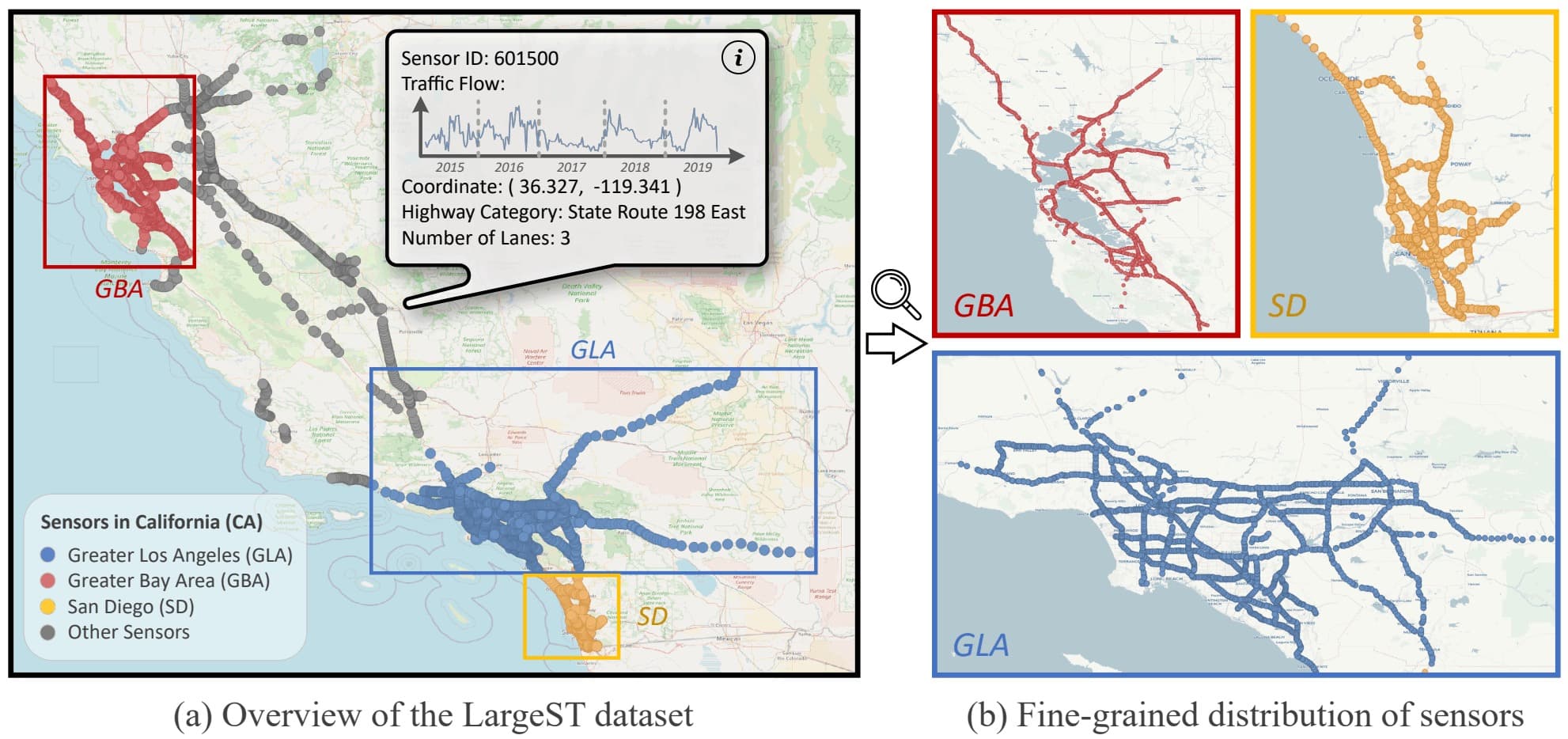
This is the official repository of our manuscript LargeST: A Benchmark Dataset for Large-Scale Traffic Forecasting. LargeST comprises four sub-datasets, each characterized by a different number of sensors. The biggest one is California (CA), including a total number of 8,600 sensors. We also construct three subsets of CA by selecting three representative areas within CA and forming the sub-datasets of Greater Los Angeles (GLA), Greater Bay Area (GBA), and San Diego (SD). The figure here shows an illustration.

In LargeST we also provide comprehensive metadata for all sensors, which are listed below.
| Attribute | Description | Possible Range of Values |
|---|---|---|
| ID | The identifier of a sensor in PeMS | 6 to 9 digits number |
| Lat | The latitude of a sensor | Real number |
| Lng | The longitude of a sensor | Real number |
| District | The district of a sensor in PeMS | 3, 4, 5, 6, 7, 8, 10, 11, 12 |
| County | The county of a sensor in California | String |
| Fwy | The highway where a sensor is located | String starts with ‘I’, ‘US’, or ‘SR’ |
| Lane | The number of lanes where a sensor is located | 1, 2, 3, 4, 5, 6, 7, 8 |
| Type | The type of a sensor | Mainline |
| Direction | The direction of the highway | N, S, E, W |
1. Data Preparation
In this section, we will outline the procedure for preparing the CA dataset, followed by an explanation of how the GLA, GBA, and SD datasets can be derived from the CA dataset. Please follow these instructions step by step.
1.1 Download the CA Dataset
We host the CA dataset on Kaggle: https://www.kaggle.com/datasets/liuxu77/largest. There are a total of 7 files in this link. Among them, 5 files in .h5 format contain the traffic flow raw data from 2017 to 2021, 1 file in .csv format provides the metadata for all sensors, and 1 file in .npy format represents the adjacency matrix constructed based on road network distances.
- If you are using the web user interface, you can download all data from the provided link. The download button is at the upper right corner of the webpage. Then please place the downloaded archive.zip file in the
data/cafolder and unzip the file. - If you would like to use the Kaggle API, please follow the instructions here. After setting the API correctly, you can simply go to the
data/cafolder, and use the command below to download all data.
kaggle datasets download liuxu77/largest
Note that the traffic flow raw data of the CA dataset require additional processing (described in Section 1.2 and 1.3), while the metadata and adjacency matrix are ready to be used.
1.2 Process Traffic Flow Data of CA
We provide a jupyter notebook process_ca_his.ipynb in the folder data/ca to process and generate a cleaned version of the flow data. Please go through this notebook.
1.3 Generate Traffic Flow Data for Training
Please go to the data folder, and use the command below to generate the flow data for model training in our manuscript.
python generate_data_for_training.py --dataset ca --years 2019
The processed data are stored in data/ca/2019. We also support the utilization of data from multiple years. For example, changing the years argument to 2018_2019 to generate two years of data.
1.4 Generate Other Sub-Datasets
We describe the generation of the GLA dataset as an example. Please first go through all the cells in the provided jupyter notebook generate_gla_dataset.ipynb in the folder data/gla. Then, use the command below to generate traffic flow data for model training.
python generate_data_for_training.py --dataset gla --years 2019
2. Experiments Running
We conduct experiments on an Intel(R) Xeon(R) Gold 6140 CPU @ 2.30 GHz, 376 GB RAM computing server, equipped with an NVIDIA RTX A6000 GPU with 48 GB memory. We adopt PyTorch 1.12 as the default deep learning library. Currently, there are a total of 11 supported baselines in this repository, namely, Historical Last (HL), LSTM, DCRNN, AGCRN, STGCN, GWNET, ASTGCN, STGODE, DSTAGNN, DGCRN, and D2STGNN.
To reproduce the benchmark results in the manuscript, please go to experiments/baseline_you_want_to_run, open the provided run.sh file, and uncomment the line you would like to execute. Note that you may need to specify the GPU card number on your server. Moreover, we use the flow data from 2019 for model training in our manuscript, if you want to use multiple years of data, please change the years argument to, e.g., 2018_2019.
To run the LSTM baseline, for example, you may execute this command in the terminal:
bash experiments/lstm/run.sh
or directly execute the Python file in the terminal:
python experiments/lstm/main.py --device cuda:2 --dataset CA --years 2019 --model_name lstm --seed 2018 --bs 32
3. Evaluate Your Model in Three Steps
You may first go through the implementations of various baselines in our repository, which may serve as good references for experimenting your own model. The steps are described as follows.
- The first step is to define the model architecture, and place it into
src/models. To ensure compatibility with the existing framework, it is recommended that your model inherits the BaseModel class (implemented insrc/base/model.py). - If your model does not require any special training or testing procedures beyond the standard workflow provided by the BaseEngine class (implemented in
src/base/engine.py), you can directly use it for training and evaluation. Otherwise, please include a file in the foldersrc/engines. - To integrate your model and engine files, you need to create a
main.pyfile in theexperiments/your_model_namedirectory.
4. License & Acknowledgement
The LargeST benchmark dataset is released under a CC BY-NC 4.0 International License: https://creativecommons.org/licenses/by-nc/4.0. Our code implementation is released under the MIT License: https://opensource.org/licenses/MIT. The license of any specific baseline methods used in our codebase should be verified on their official repositories. Here we would also like to express our gratitude to the authors of baselines for releasing their code.
5. Citation
If you find our work useful in your research, please cite:
@article{liu2023large,
title={LargeST: A Benchmark Dataset for Large-Scale Traffic Forecasting},
author={Liu, Xu and Xia, Yutong and Liang, Yuxuan and Hu, Junfeng and Wang, Yiwei and Bai, Lei and Huang, Chao and Liu, Zhenguang and Hooi, Bryan and Zimmermann, Roger},
journal={arXiv preprint arXiv:2306.08259},
year={2023}
}